SpeciesPoolR
![]()
The goal of the SpeciesPoolR package is to generate potential species pools and their summary metrics in a spatial way. You can install the package directly from GitHub:
#install.packages("remotes")
remotes::install_github("derek-corcoran-barrios/SpeciesPoolR")No you can load the package
Motivation for the pacakge
Rare species are common and important
In ecological research, the debate on whether rare species outnumber common species within communities is pivotal for understanding biodiversity and guiding conservation efforts. Numerous studies have shown that rare species typically dominate large ecological assemblages, although common species often exert a more substantial influence on overall species richness patterns (Magurran and Henderson 2003; Bregović, Fišer, and Zagmajster 2019; Schalkwyk, Pryke, and Samways 2019). This complexity underscores the need for innovative approaches in studying biodiversity, particularly since rare species are challenging to model using traditional Species Distribution Models (SDMs) due to their low occurrence rates (Boyd et al. 2022).
Given the limitations of SDMs in capturing the dynamics of rare species, it is essential to develop alternative methods for integrating these species into biodiversity assessments and conservation planning. Although rare species contribute uniquely to functional diversity and ecosystem stability, especially in specific habitats (Chapman, Tunnicliffe, and Bates 2018; Säterberg et al. 2019), their elusiveness in ecological models presents a significant challenge. The question of the minimum number of presence records required for reliable SDMs is crucial. Research has shown that while as few as 10-15 presence observations can produce nonrandom models for some species (Støa et al. 2019), others require higher thresholds—ranging from 14 to 25 records depending on the species’ prevalence and geographic range (Proosdij et al. 2016; Sampaio and Cavalcante 2023). These findings suggest that even sparse datasets can be useful, but the threshold varies significantly depending on species traits and habitat characteristics. Therefore, researchers must explore novel analytical frameworks and conservation strategies that better accommodate the ecological importance of rare species, thereby enhancing our ability to manage and preserve biodiversity effectively (Reddin, Bothwell, and Lennon 2015).
In highly degraded habitats, such as Denmark, where over 60% of the land is dominated by agriculture and less than 10% remains as natural habitat, traditional SDMs may face further limitations. The scarcity of natural habitats means that presence records are often skewed towards human-modified landscapes, complicating the modeling of species’ ecological preferences. In such contexts, where the majority of occurrences may not reflect the species’ natural behaviors or habitat use, relying on complex SDMs could lead to misleading predictions. Instead, simpler algorithms that incorporate basic dispersal mechanisms and habitat filtering might be more effective. By reducing assumptions about habitat preferences, these methods can provide a more realistic framework for conservation planning, particularly when dealing with the restoration of agricultural lands into natural habitats.
For rare species, and indeed for many others, this approach may offer a more practical solution in scenarios where detailed ecological data is sparse or unreliable. Studies have suggested that in such landscapes, simplistic models that prioritize dispersal and broad habitat suitability over intricate ecological niches can better capture species’ potential distributions and their responses to environmental changes (Guisan et al. 2006; Thuiller et al. 2005), an example to this approach would be range bagging (Drake 2015). This pragmatic approach is especially pertinent when planning conservation actions in areas where habitat degradation has left little intact nature, and it ensures that even under data constraints, effective biodiversity management can still be pursued.
Required Data Files
To effectively execute the SpeciesPoolR workflow, a set
of essential data files must be provided. These files contain the
necessary spatial and taxonomic information that underpin the various
analytical steps in the package. Below, we detail each required file and
its role within the workflow.
Species List File
File Type: CSV or Excel file
Description: The species list file serves as the foundational dataset, comprising the species of interest for your analysis. At a minimum, this file must include a column for the scientific names of species (
Species). Additional taxonomic columns, such asKingdom,Class, andFamily, may also be included to facilitate filtering and subgroup analyses.
An example of this file is provided within the package and can be accessed using the following code:
exampleSpecies <- system.file("ex/Species_List.csv", package="SpeciesPoolR")
print(exampleSpecies)
#> [1] "/home/runner/work/_temp/Library/SpeciesPoolR/ex/Species_List.csv"This dataset is further discussed in the section on Reading and Filtering Data, with a filtered subset displayed in Table @ref(tab:tablespecies).
Shapefile
File Type: Shapefile (.shp)
Description: The shapefile delineates the geographic area of interest, which can range from a broad region, such as a country, to a more specific locality, such as a nature reserve. This file is utilized to spatially constrain species occurrences, ensuring that only those within the defined boundaries are included in the analysis.
If a shapefile is unavailable, a two-letter country code (e.g., “DK” for Denmark) may be provided as an alternative to specify the area of interest.
An example shapefile is included in the package and can be accessed as follows:
shp <- system.file("ex/Aarhus.shp", package="SpeciesPoolR")
print(shp)
#> [1] "/home/runner/work/_temp/Library/SpeciesPoolR/ex/Aarhus.shp"The shapefile’s application is illustrated in the section on Counting Species Presences, where it is used to delineate the boundaries of Aarhus commune, as shown in Figure @ref(fig:plotshapefile).
Outline of the comune of Aarhus
Raster Template File
File Type: Raster file (e.g., .tif)
Description: The raster template file is employed as a spatial reference for rasterizing species presence buffers. It must cover the entire area of interest and possess a resolution appropriate for the intended analysis. This template ensures consistent spatial alignment across all raster-based operations.
You can explore an example of this file using the following code:
template <- system.file("ex/LU_Aarhus.tif", package="SpeciesPoolR")
print(template)
#> [1] "/home/runner/work/_temp/Library/SpeciesPoolR/ex/LU_Aarhus.tif"The raster template’s role in buffer creation is further explained in the section on Creating Buffers Around Species Presences, with an example shown in Figure @ref(fig:plottemplate).
Raster of the Aarhus comune, the package will use Non NA cells as part of the template
Land-Use Raster File
File Type: Raster file (e.g., .tif)
Description: This file contains land-use classifications for the study area, where each raster cell is assigned to a specific land-use category (e.g., forest, wetland, urban). This data is crucial for modeling habitat suitability, enabling the filtering of species occurrences based on the prevalent land uses within their potential habitats.
An example file is provided in the package:
LU <- system.file("ex/LU_Aarhus.tif", package="SpeciesPoolR")
print(LU)
#> [1] "/home/runner/work/_temp/Library/SpeciesPoolR/ex/LU_Aarhus.tif"The land-use raster is identical to the template shown in Figure @ref(fig:plottemplate).
Land-Use Suitability Raster File
File Type: Raster file (e.g., .tif)
Description: This file comprises binary suitability values for various land-use types within the study area, indicating whether each land-use type is suitable (value = 1) or unsuitable (value = 0) for the habitat of interest. The data is subsequently transformed into a long-format table, which is integral to the habitat filtering and species distribution modeling processes.
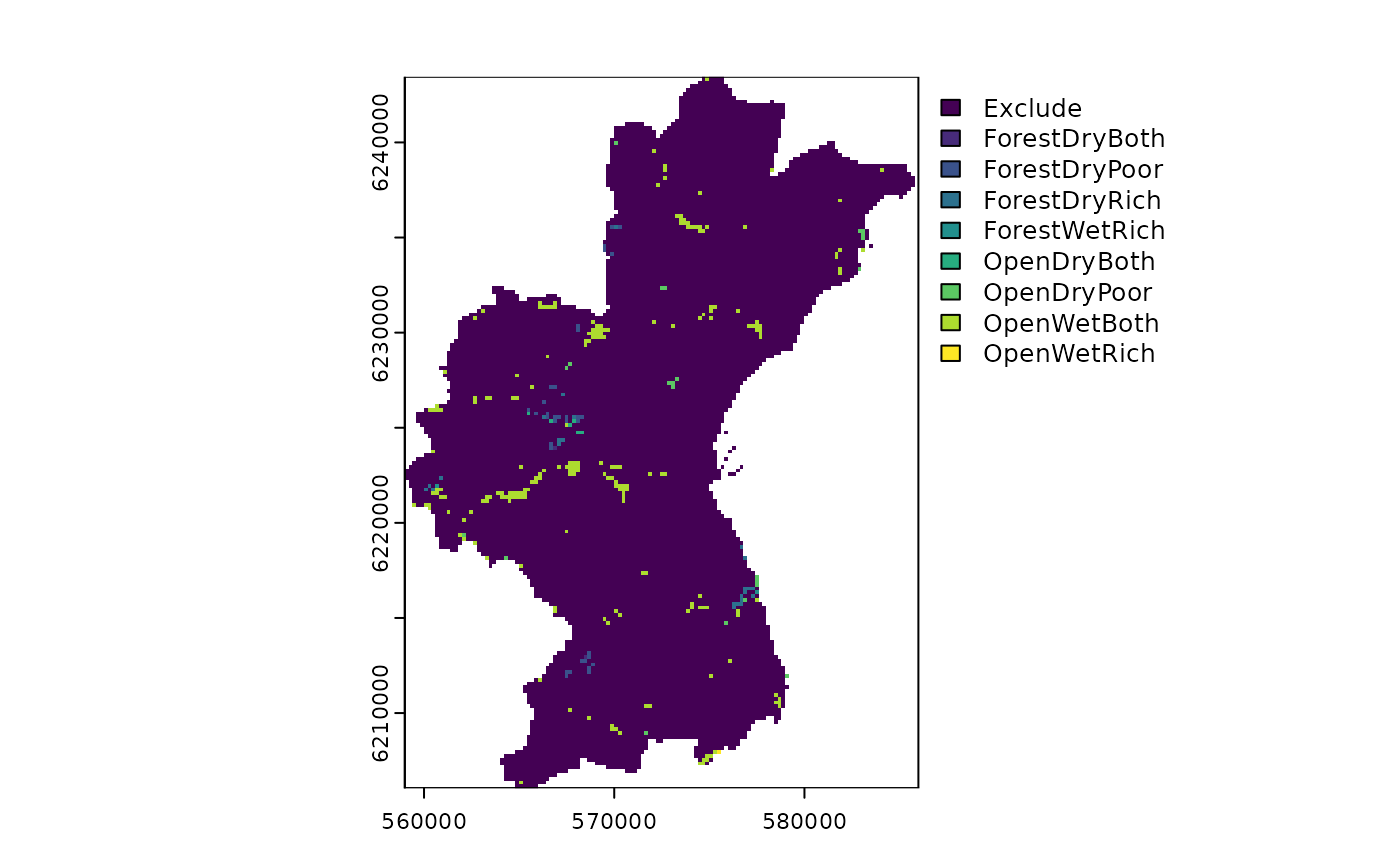
An example raster file is available in the package, and its application is discussed in the section on Preparing Land-Use Data. A visualization of this file is presented in Figure @ref(fig:plotexampleLU).

Landuse suitability for 8 different landuses in the aarhus commune
Using SpeciesPoolR Manually
Importing and Downloading Species Presences
Step 1: Reading and Filtering Data
If you are going to use each of the functions of the SpeciesPoolR manually and sequentially, the first step would be to read in a species list from either a CSV or an XLSX file. You can use the get_data function for this. The function allows you to filter your data in a dplyr-like style:
f <- system.file("ex/Species_List.csv", package="SpeciesPoolR")
filtered_data <- get_data(
file = f,
filter = quote(Kingdom == "Plantae" &
Class == "Magnoliopsida" &
Family == "Fabaceae")
)
#> Rows: 200 Columns: 8
#> ── Column specification ────────────────────────────────────────────────────────
#> Delimiter: ","
#> chr (8): redlist_2010, Kingdom, Phyllum, Class, Order, Family, Genus, Species
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.This will generate a dataset that can be used subsequently to count species presences and download species data as seen in table @ref(tab:tablespecies)
| redlist_2010 | Kingdom | Phyllum | Class | Order | Family | Genus | Species |
|---|---|---|---|---|---|---|---|
| NA | Plantae | Magnoliophyta | Magnoliopsida | Fabales | Fabaceae | Vicia | Vicia sepium |
| NA | Plantae | Magnoliophyta | Magnoliopsida | Fabales | Fabaceae | Genista | Genista tinctoria |
| NA | Plantae | Magnoliophyta | Magnoliopsida | Fabales | Fabaceae | Trifolium | Trifolium vesiculosum |
| LC | Plantae | Magnoliophyta | Magnoliopsida | Fabales | Fabaceae | Vicia | Vicia sativa |
| NA | Plantae | Magnoliophyta | Magnoliopsida | Fabales | Fabaceae | Lathyrus | Lathyrus latifolius |
| NA | Plantae | Magnoliophyta | Magnoliopsida | Fabales | Fabaceae | Anthyllis | Anthyllis vulneraria |
| NA | Plantae | Magnoliophyta | Magnoliopsida | Fabales | Fabaceae | Vicia | Vicia sepium |
| NA | Plantae | Magnoliophyta | Magnoliopsida | Fabales | Fabaceae | Lathyrus | Lathyrus japonicus |
| NA | Plantae | Magnoliophyta | Magnoliopsida | Fabales | Fabaceae | Vicia | Vicia villosa |
Step 2: Taxonomic Harmonization
Next, you should perform taxonomic harmonization to ensure that the species names you use are recognized by the GBIF taxonomic backbone. This can be done using the Clean_Taxa function:
Clean_Species <- SpeciesPoolR::Clean_Taxa(filtered_data$Species)
#> Joining with `by = join_by(Taxa)`
#> Joining with `by = join_by(matched_name2)`The resulting data frame, with harmonized species names, is shown in table @ref(tab:cleantable)
| Taxa | matched_name2 | confidence | canonicalName | kingdom | phylum | class | order | family | genus | species | rank |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Vicia sepium | Vicia sepium | 99 | Vicia sepium | Plantae | Tracheophyta | Magnoliopsida | Fabales | Fabaceae | Vicia | Vicia sepium | SPECIES |
| Genista tinctoria | Genista tinctoria | 99 | Genista tinctoria | Plantae | Tracheophyta | Magnoliopsida | Fabales | Fabaceae | Genista | Genista tinctoria | SPECIES |
| Trifolium vesiculosum | Trifolium vesiculosum | 99 | Trifolium vesiculosum | Plantae | Tracheophyta | Magnoliopsida | Fabales | Fabaceae | Trifolium | Trifolium vesiculosum | SPECIES |
| Vicia sativa | Vicia sativa | 97 | Vicia sativa | Plantae | Tracheophyta | Magnoliopsida | Fabales | Fabaceae | Vicia | Vicia sativa | SPECIES |
| Lathyrus latifolius | Lathyrus latifolius | 98 | Lathyrus latifolius | Plantae | Tracheophyta | Magnoliopsida | Fabales | Fabaceae | Lathyrus | Lathyrus latifolius | SPECIES |
| Anthyllis vulneraria | Anthyllis vulneraria | 97 | Anthyllis vulneraria | Plantae | Tracheophyta | Magnoliopsida | Fabales | Fabaceae | Anthyllis | Anthyllis vulneraria | SPECIES |
| Lathyrus japonicus | Lathyrus japonicus | 99 | Lathyrus japonicus | Plantae | Tracheophyta | Magnoliopsida | Fabales | Fabaceae | Lathyrus | Lathyrus japonicus | SPECIES |
| Vicia villosa | Vicia villosa | 97 | Vicia villosa | Plantae | Tracheophyta | Magnoliopsida | Fabales | Fabaceae | Vicia | Vicia villosa | SPECIES |
Step 3: Counting Species Presences
After harmonizing the species names, it’s important to obtain the
number of occurrences of each species in your study area, especially if
you plan to calculate rarity. You can do this using the
count_presences function. This function allows you to
filter occurrences by country or by a shapefile. Below is an example for
Denmark:
# Assuming Clean_Species is your data frame
Count_DK <- count_presences(Clean_Species, country = "DK")The resulting data frame of species presences in Denmark is shown in table @ref(tab:tableCountDenmark)
knitr::kable(Count_DK, caption = "Counts of presences for the different species within Denmark")| family | genus | species | N |
|---|---|---|---|
| Fabaceae | Vicia | Vicia sepium | 2901 |
| Fabaceae | Genista | Genista tinctoria | 988 |
| Fabaceae | Trifolium | Trifolium vesiculosum | 0 |
| Fabaceae | Vicia | Vicia sativa | 17380 |
| Fabaceae | Lathyrus | Lathyrus latifolius | 685 |
| Fabaceae | Anthyllis | Anthyllis vulneraria | 8880 |
| Fabaceae | Lathyrus | Lathyrus japonicus | 3905 |
| Fabaceae | Vicia | Vicia villosa | 243 |
Alternatively, you can filter by a specific region using a shapefile. For example, to count species presences within Aarhus commune:
shp <- system.file("ex/Aarhus.shp", package="SpeciesPoolR")
Count_Aarhus <- count_presences(Clean_Species, shapefile = shp)The resulting data.frame for Aarhus commune is shown int table @ref(tab:tableCountAarhus)
| family | genus | species | N |
|---|---|---|---|
| Fabaceae | Vicia | Vicia sepium | 283 |
| Fabaceae | Genista | Genista tinctoria | 27 |
| Fabaceae | Trifolium | Trifolium vesiculosum | 0 |
| Fabaceae | Vicia | Vicia sativa | 467 |
| Fabaceae | Lathyrus | Lathyrus latifolius | 41 |
| Fabaceae | Anthyllis | Anthyllis vulneraria | 153 |
| Fabaceae | Lathyrus | Lathyrus japonicus | 39 |
| Fabaceae | Vicia | Vicia villosa | 10 |
Now it is recommended to eliminate species that have no occurrences in the area, this is done automatically in the workflow version:
library(data.table)
#>
#> Attaching package: 'data.table'
#> The following object is masked from 'package:terra':
#>
#> shift
Count_Aarhus <- Count_Aarhus[N > 0,]So that then we can retrieve the species presences using the function
SpeciesPoolR::get_presences.
Presences <- get_presences(species = Count_Aarhus$species, shapefile = shp)
#> [1] "Geometry created: POLYGON ((10.401438 56.302419, 10.048024 56.355225, 9.886316 56.019928, 10.239729 55.966657, 10.401438 56.302419))"
#> Starting species 1
#> 1 of 7 ready! 2024-10-10 04:11:04.984473
#> Starting species 2
#> 2 of 7 ready! 2024-10-10 04:11:05.39457
#> Starting species 3
#> 3 of 7 ready! 2024-10-10 04:11:06.541133
#> Starting species 4
#> 4 of 7 ready! 2024-10-10 04:11:06.972213
#> Starting species 5
#> 5 of 7 ready! 2024-10-10 04:11:07.677538
#> Starting species 6
#> 6 of 7 ready! 2024-10-10 04:11:08.106399
#> Starting species 7
#> 7 of 7 ready! 2024-10-10 04:11:08.511867there we end up with 1077 presences for our 7 species.
Creating Spatial Buffers and Habitat Filtering
Step 1 Creating Buffers Around Species Presences
Once you have identified the species presences within your area of interest, the next step is to create spatial buffers around these occurrences. These buffers represent the potential dispersal range of each species, helping to assess areas where the species might establish itself given a specified dispersal distance.
To create these buffers, you’ll use a raster file as a template to rasterize the buffers and specify the distance (in meters) representing the species’ dispersal range.
Raster <- system.file("ex/LU_Aarhus.tif", package="SpeciesPoolR")
buffer500 <- make_buffer_rasterized(Presences, file = Raster, dist = 500)In this example, the make_buffer_rasterized function generates a 500-meter buffer around each occurrence point in the Presences dataset. The function utilizes the provided raster file as a template for rasterizing these buffers.
The resulting buffer500 data frame indicates which raster cells are covered by the buffer for each species. Table @ref(tab:showbuffer500) displays the first 10 observations of this data frame, providing a detailed view of the buffer’s overlap with raster cells, listing each cell and the corresponding species within that buffer.
| cell | species |
|---|---|
| 26 | Vicia sepium |
| 27 | Vicia sepium |
| 28 | Vicia sepium |
| 29 | Vicia sepium |
| 30 | Vicia sepium |
| 161 | Vicia sepium |
| 162 | Vicia sepium |
| 163 | Vicia sepium |
| 164 | Vicia sepium |
| 165 | Vicia sepium |
This table provides a detailed view of how the buffer overlaps with the raster cells, listing each cell and the corresponding species present within that buffer.
Step 2: Habitat Filtering
After creating the buffers, the next logical step is to filter these areas based on habitat suitability. This allows you to focus on specific land-use types or habitats where the species is more likely to thrive. Habitat filtering typically involves using raster data to refine or subset the buffer areas according to the desired habitat criteria.
Preparing Land-Use Data
Before you can apply habitat filtering, you need to prepare a long-format land-use table that matches each raster cell to its corresponding habitat types. This is done using the generate_long_landuse_table function, which takes the path to your raster file and transforms it into a long-format data frame. The function also filters the data to include only those cells where the suitability value is 1 for at least one land-use type.
# Get path for habitat suitability
HabSut <- system.file("ex/HabSut.tif", package = "SpeciesPoolR")
# Generate the long-format land-use table
long_LU_table <- generate_long_landuse_table(path = HabSut)This is crucial for the next steps, the result is shown in table @ref(tab:longtablehab), as it links each raster cell to potential habitats, enabling you to match species occurrences to suitable environments within their buffer zones.
| cell | Habitat |
|---|---|
| 79 | OpenDryPoor |
| 80 | OpenDryPoor |
| 81 | OpenDryPoor |
| 82 | OpenDryPoor |
| 83 | OpenDryPoor |
| 214 | OpenDryPoor |
| 215 | OpenDryPoor |
| 216 | OpenDryPoor |
| 217 | OpenDryPoor |
| 218 | OpenDryPoor |
Applying Habitat Filtering
Once you have the long-format land-use table, you can proceed with
habitat filtering. To achieve this, you’ll use the
ModelAndPredictFunc, which takes the presence data frame
(e.g., Presences) obtained through the get_presences function and the
land-use raster. This comprehensive function encompasses several
critical steps:
1- Grouping Data by Species: The presence data is grouped by
species using group_split, ensuring that each species is
modeled individually.
2- Sampling Land-Use Data: For each species, land-use data is sampled at the presence points using the SampleLanduse function.
3- Sampling Background Data: Background points are also sampled from the same land-use raster, providing a contrast to the presence data.
4- Modeling Habitat Suitability: The presence and background
data are combined and passed to the ModelSpecies function.
This function fits a MaxEnt model to predict habitat suitability across
the different land-use types.
5- Predicting Suitability: The fitted model is then used to predict habitat suitability for each species across all available land-use types.
Habitats <- ModelAndPredictFunc(DF = Presences, file = Raster)
#> Warning: [spatSample] fewer values returned than requested
#> Warning: [spatSample] fewer values returned than requested
#> Warning in lognet(xd, is.sparse, ix, jx, y, weights, offset, alpha, nobs, : one
#> multinomial or binomial class has fewer than 8 observations; dangerous ground
#> Warning: [spatSample] requested sample size is larger than the number of cells
#> Warning: [spatSample] more non-NA cells requested than available
#> Warning in lognet(xd, is.sparse, ix, jx, y, weights, offset, alpha, nobs, : one
#> multinomial or binomial class has fewer than 8 observations; dangerous groundThe resulting Habitats data frame contains continuous suitability predictions for each species across various land-use types. Table @ref(tab:tablespeciespred) shows the first 9 observations, illustrating the predicted habitat suitability scores for the first species in each land-use type.
knitr::kable(Habitats[1:9,], caption = "Predicted habitat suitability scores across various land-use types for the first species. The values represent continuous predictions, indicating the relative likelihood of species presence in each land-use category.")| Landuse | Pred | species |
|---|---|---|
| OpenDryRich | 1.0000000 | Anthyllis vulneraria |
| OpenDryPoor | 1.0000000 | Anthyllis vulneraria |
| ForestWetRich | 0.6656339 | Anthyllis vulneraria |
| OpenWetRich | 0.6656339 | Anthyllis vulneraria |
| OpenWetPoor | 0.6656339 | Anthyllis vulneraria |
| Exclude | 0.5122440 | Anthyllis vulneraria |
| ForestDryRich | 0.3093417 | Anthyllis vulneraria |
| ForestDryPoor | 0.2246560 | Anthyllis vulneraria |
| Exclude | 0.6335459 | Genista tinctoria |
Step 3: Generating Habitat Suitability Thresholds
While continuous predictions provide a detailed picture of habitat suitability, it is often useful to classify these predictions into binary suitability thresholds. Thresholds can help determine areas where species presence is more likely or unlikely based on habitat preferences.
The create_thresholds function facilitates this by generating thresholds based on the modeled land-use preferences, using the 90th, 95th, and 99th percentiles of the predicted suitability values. These thresholds represent the commission rates, helping to define the probability cutoff above which a land-use type is considered suitable for a species.
Here’s how you can generate these thresholds for the species in your dataset:
Thresholds <- create_thresholds(Model = Habitats, reference = Presences, file = Raster)This will generate de data set with the threshold for the comission rates of 90, 95 and 99th percentile for each species that can be seen in Table @ref(tab:thresholdtables).
| species | Thres_99 | Thres_95 | Thres_90 |
|---|---|---|---|
| Anthyllis vulneraria | 0.512 | 0.512 | 0.512 |
| Genista tinctoria | 0.634 | 0.634 | 0.634 |
| Lathyrus japonicus | 0.407 | 0.407 | 0.407 |
| Lathyrus latifolius | 0.634 | 0.634 | 0.634 |
| Vicia sativa | 0.404 | 0.404 | 0.404 |
| Vicia sepium | 0.292 | 0.292 | 0.292 |
| Vicia villosa | 0.634 | 0.634 | 0.634 |
This step produces a data frame containing the thresholds for each species, which can then be used to classify habitat suitability into binary categories, helping you to identify core habitats or areas of higher conservation value.
After we have the continuous thresholds we can generate a lookup table to see which species can inhabit in each landuse type
LookupTable <- Generate_Lookup(Model = Habitats, Thresholds = Thresholds)This creates Table @ref(tab:lookuptab), notice how it only shows for each species which habitats are available not the ones that are not.
| species | Landuse | Pres |
|---|---|---|
| Anthyllis vulneraria | OpenDryRich | 1 |
| Anthyllis vulneraria | OpenDryPoor | 1 |
| Anthyllis vulneraria | ForestWetRich | 1 |
| Anthyllis vulneraria | OpenWetRich | 1 |
| Anthyllis vulneraria | OpenWetPoor | 1 |
| Lathyrus japonicus | OpenDryPoor | 1 |
| Vicia sativa | OpenDryPoor | 1 |
| Vicia sativa | OpenDryRich | 1 |
| Vicia sativa | OpenWetPoor | 1 |
| Vicia sativa | OpenWetRich | 1 |
| Vicia sativa | ForestWetRich | 1 |
| Vicia sativa | ForestDryRich | 1 |
| Vicia sepium | ForestWetRich | 1 |
| Vicia sepium | ForestDryRich | 1 |
| Vicia sepium | OpenDryPoor | 1 |
| Vicia sepium | OpenWetRich | 1 |
| Vicia sepium | OpenWetPoor | 1 |
| Vicia sepium | OpenDryRich | 1 |
Step 4: Generating Final Species Presences
In this final step, we apply the make_final_presences
function to filter the buffered species presences. This filtering
process is done in three stages:
Lookup Table Filtering: The function first ensures that each species is only considered in habitats where it can persist based on the species-habitat suitability mappings in the lookup table.
Land-Use Table Filtering: Next, it filters these suitable habitats to include only those cells where the specific habitat type could exist, based on the long-format land-use table.
Buffer Zone Filtering: Finally, it restricts the potential species occurrences to areas where the species is likely to disperse, as indicated by the spatial buffers generated around species presence points.
The result is a highly refined dataset that specifies, for each species, the exact cells and habitat types where it can potentially occur, combining habitat suitability, land-use distribution, and species dispersal capability.
final_presences <- make_final_presences(Long_LU_table = long_LU_table,
Long_Buffer_gbif = buffer500,
LookUpTable = LookupTable)The resulting final_presences table provides detailed
information on the potential distribution of each species. It specifies
which cells and habitats are suitable for each species, ensuring that
only the most plausible locations are considered. In table
@(tab:finalpresences), you can see the first 15 observations from this
final dataset, which represent the potential habitats where each species
could thrive, whereas in table @(tab:summaryfinalpresences), you can see
a summary of the number of cells that each species could thrive on each
habitat type.
| cell | species | Landuse |
|---|---|---|
| 1018 | Anthyllis vulneraria | OpenDryRich |
| 1557 | Anthyllis vulneraria | OpenDryRich |
| 1825 | Anthyllis vulneraria | OpenDryRich |
| 2093 | Anthyllis vulneraria | OpenDryRich |
| 2215 | Anthyllis vulneraria | OpenDryRich |
| 2216 | Anthyllis vulneraria | OpenDryRich |
| 2218 | Anthyllis vulneraria | OpenDryRich |
| 2351 | Anthyllis vulneraria | OpenDryRich |
| 2352 | Anthyllis vulneraria | OpenDryRich |
| 2353 | Anthyllis vulneraria | OpenDryRich |
| 2354 | Anthyllis vulneraria | OpenDryRich |
| 2486 | Anthyllis vulneraria | OpenDryRich |
| 2488 | Anthyllis vulneraria | OpenDryRich |
| 2489 | Anthyllis vulneraria | OpenDryRich |
| 2620 | Anthyllis vulneraria | OpenDryRich |
#> `summarise()` has grouped output by 'Landuse'. You can override using the
#> `.groups` argument.| Landuse | species | N |
|---|---|---|
| OpenDryRich | Anthyllis vulneraria | 802 |
| ForestWetRich | Anthyllis vulneraria | 512 |
| OpenWetRich | Anthyllis vulneraria | 512 |
| ForestDryRich | Vicia sepium | 254 |
| OpenDryRich | Vicia sepium | 254 |
| ForestWetRich | Vicia sepium | 141 |
| OpenWetRich | Vicia sepium | 141 |
| OpenWetPoor | Anthyllis vulneraria | 126 |
| OpenDryPoor | Anthyllis vulneraria | 70 |
| OpenDryPoor | Lathyrus japonicus | 47 |
| OpenWetPoor | Vicia sepium | 31 |
| ForestDryRich | Vicia sativa | 26 |
| OpenDryRich | Vicia sativa | 26 |
| ForestWetRich | Vicia sativa | 18 |
| OpenWetRich | Vicia sativa | 18 |
| OpenDryPoor | Vicia sepium | 16 |
| OpenWetPoor | Vicia sativa | 7 |
Generating summary biodiversity statistics
Step 1 Generating Phylogenetic diversity metrics
In order to generate Phylogenetic Diversity measures, the first step
is to generate a phylogenetic tree with the species we have, for that we
will use the V.Phylomaker package function phylo.makerbased
on the megaphylogeny of vascular plants (Jin and
Qian 2019; Zanne et al. 2014), this means that we can only use
this functions in species pools of plants.
In this case we use the generate_tree from SpeciesPoolR
to do so:
tree <- generate_tree(Count_Aarhus)
#> [1] "All species in sp.list are present on tree."Running the SpeciesPoolR Workflow
If you prefer to automate the process and run the
SpeciesPoolR workflow as a pipeline, you can use the
run_workflow function. This function sets up a
targets workflow that sequentially executes the steps for
cleaning species data, counting species presences, and performing
spatial analysis. This approach is especially useful for larger datasets
or when you want to ensure reproducibility.
To run the workflow, you can use the following code. We’ll use the
same species filter as before, focusing on the Plantae
kingdom, Magnoliopsida class, and Fabaceae
family. Additionally, we’ll focus on the Aarhus commune using a
shapefile.
shp <- system.file("ex/Aarhus.shp", package = "SpeciesPoolR")
Raster <- system.file("ex/LU_Aarhus.tif", package="SpeciesPoolR")
HabSut <- system.file("ex/HabSut.tif", package = "SpeciesPoolR")
run_workflow(
file_path = system.file("ex/Species_List.csv", package = "SpeciesPoolR"),
filter = quote(Kingdom == "Plantae" & Class == "Magnoliopsida" & Family == "Fabaceae"),
shapefile = shp,
dist = 500,
rastertemp = Raster,
rasterLU = Raster,
LanduseSuitability = HabSut
)
#> ▶ dispatched target shp
#> ▶ dispatched target Raster
#> ● completed target Raster [3.608 seconds, 3.169 kilobytes]
#> ▶ dispatched target Landuses
#> ● completed target Landuses [0 seconds, 3.169 kilobytes]
#> ▶ dispatched target file
#> ● completed target file [0 seconds, 16.964 kilobytes]
#> ▶ dispatched target data
#> ● completed target shp [3.681 seconds, 25.548 kilobytes]
#> ▶ dispatched target Landusesuitability
#> ● completed target Landusesuitability [0 seconds, 20.886 kilobytes]
#> ▶ dispatched target Long_LU_table
#> ● completed target Long_LU_table [0.054 seconds, 12.08 kilobytes]
#> ● completed target data [0.167 seconds, 525 bytes]
#> ▶ dispatched target Clean
#> ● completed target Clean [1.431 seconds, 583 bytes]
#> ▶ dispatched branch Count_Presences_33538e94b3809372
#> ▶ dispatched branch Count_Presences_52d72a5ad405e933
#> ● completed branch Count_Presences_33538e94b3809372 [1.046 seconds, 209 bytes]
#> ▶ dispatched branch Count_Presences_e70f77d9439a4770
#> ● completed branch Count_Presences_52d72a5ad405e933 [1.108 seconds, 208 bytes]
#> ▶ dispatched branch Count_Presences_dea4ef8633a449a1
#> ● completed branch Count_Presences_e70f77d9439a4770 [0.461 seconds, 209 bytes]
#> ▶ dispatched branch Count_Presences_69210fc440d13855
#> ● completed branch Count_Presences_dea4ef8633a449a1 [0.41 seconds, 208 bytes]
#> ▶ dispatched branch Count_Presences_a61be030e01ebaf5
#> ● completed branch Count_Presences_69210fc440d13855 [0.406 seconds, 211 bytes]
#> ▶ dispatched branch Count_Presences_974105e269324d3e
#> ● completed branch Count_Presences_a61be030e01ebaf5 [0.411 seconds, 213 bytes]
#> ▶ dispatched branch Count_Presences_37d1f8d5f74d852c
#> ● completed branch Count_Presences_37d1f8d5f74d852c [0.658 seconds, 206 bytes]
#> ● completed branch Count_Presences_974105e269324d3e [0.695 seconds, 212 bytes]
#> ● completed pattern Count_Presences
#> ▶ dispatched target More_than_zero
#> ● completed target More_than_zero [0.001 seconds, 335 bytes]
#> ▶ dispatched branch Presences_c112b37cd15959d6
#> ▶ dispatched branch Presences_af64bac105a08467
#> ● completed branch Presences_af64bac105a08467 [1.667 seconds, 707 bytes]
#> ▶ dispatched branch ModelAndPredict_0e19b8cb545404d2
#> ● completed branch ModelAndPredict_0e19b8cb545404d2 [0.705 seconds, 301 bytes]
#> ▶ dispatched branch Presences_daf8d6353bc80f0c
#> ● completed branch Presences_c112b37cd15959d6 [3.253 seconds, 4.431 kilobytes]
#> ▶ dispatched branch ModelAndPredict_626a53b08dfe709d
#> ● completed branch Presences_daf8d6353bc80f0c [3.189 seconds, 7.013 kilobytes]
#> ▶ dispatched branch ModelAndPredict_edb09c8ec5c9a988
#> ● completed branch ModelAndPredict_626a53b08dfe709d [9.654 seconds, 329 bytes]
#> ▶ dispatched branch Presences_310adeccf6b44725
#> ● completed branch Presences_310adeccf6b44725 [1.85 seconds, 958 bytes]
#> ▶ dispatched branch ModelAndPredict_b226446ac3154351
#> ● completed branch ModelAndPredict_edb09c8ec5c9a988 [12.43 seconds, 328 bytes]
#> ▶ dispatched branch Presences_e65f4227e8299cc4
#> ● completed branch ModelAndPredict_b226446ac3154351 [3.464 seconds, 303 bytes]
#> ▶ dispatched branch Presences_d4b9dc68293bd5b2
#> ● completed branch Presences_d4b9dc68293bd5b2 [1.437 seconds, 847 bytes]
#> ▶ dispatched branch ModelAndPredict_cae8301e59fc4e01
#> ● completed branch ModelAndPredict_cae8301e59fc4e01 [0.409 seconds, 328 bytes]
#> ▶ dispatched branch Presences_88937156c1302a12
#> ● completed branch Presences_e65f4227e8299cc4 [2.325 seconds, 2.753 kilobytes]
#> ▶ dispatched branch ModelAndPredict_0a8436ee3d4f2644
#> ● completed branch Presences_88937156c1302a12 [0.87 seconds, 461 bytes]
#> ● completed pattern Presences
#> ▶ dispatched branch ModelAndPredict_a0190cbfdf5f6f1f
#> ● completed branch ModelAndPredict_a0190cbfdf5f6f1f [0.274 seconds, 297 bytes]
#> ▶ dispatched target Phylo_Tree
#> ● completed branch ModelAndPredict_0a8436ee3d4f2644 [4.143 seconds, 328 bytes]
#> ● completed pattern ModelAndPredict
#> ▶ dispatched target Thresholds
#> ● completed target Thresholds [0.269 seconds, 309 bytes]
#> ▶ dispatched target LookUpTable
#> ● completed target LookUpTable [0.008 seconds, 323 bytes]
#> ▶ dispatched target rarity_weight
#> ● completed target rarity_weight [0.002 seconds, 311 bytes]
#> ▶ dispatched branch buffer_0e19b8cb545404d2
#> ● completed branch buffer_0e19b8cb545404d2 [0.035 seconds, 868 bytes]
#> ▶ dispatched branch Final_Presences_344cc771c9264c2e
#> ● completed branch Final_Presences_344cc771c9264c2e [0.006 seconds, 169 bytes]
#> ▶ dispatched branch buffer_626a53b08dfe709d
#> ● completed branch buffer_626a53b08dfe709d [0.109 seconds, 7.248 kilobytes]
#> ▶ dispatched branch Final_Presences_ebf0f62f14548a82
#> ● completed branch Final_Presences_ebf0f62f14548a82 [0.009 seconds, 2.47 kilobytes]
#> ▶ dispatched branch buffer_edb09c8ec5c9a988
#> ● completed branch buffer_edb09c8ec5c9a988 [0.028 seconds, 11.252 kilobytes]
#> ▶ dispatched branch Final_Presences_6f1885e07badc469
#> ● completed branch Final_Presences_6f1885e07badc469 [0.01 seconds, 3.531 kilobytes]
#> ▶ dispatched branch buffer_b226446ac3154351
#> ● completed branch buffer_b226446ac3154351 [0.029 seconds, 1.815 kilobytes]
#> ▶ dispatched branch Final_Presences_35ecd9eff835718c
#> ● completed branch Final_Presences_35ecd9eff835718c [0.007 seconds, 169 bytes]
#> ▶ dispatched branch buffer_cae8301e59fc4e01
#> ● completed branch buffer_cae8301e59fc4e01 [0.019 seconds, 537 bytes]
#> ▶ dispatched branch Final_Presences_5224d468624d4ebb
#> ● completed branch Final_Presences_5224d468624d4ebb [0.006 seconds, 169 bytes]
#> ▶ dispatched branch buffer_0a8436ee3d4f2644
#> ● completed branch buffer_0a8436ee3d4f2644 [0.022 seconds, 4.84 kilobytes]
#> ▶ dispatched branch Final_Presences_af0c167a6a4b9998
#> ● completed branch Final_Presences_af0c167a6a4b9998 [0.007 seconds, 1.181 kilobytes]
#> ▶ dispatched branch buffer_a0190cbfdf5f6f1f
#> ● completed branch buffer_a0190cbfdf5f6f1f [0.018 seconds, 522 bytes]
#> ● completed pattern buffer
#> ▶ dispatched branch Final_Presences_d203d619aa280fd1
#> ● completed branch Final_Presences_d203d619aa280fd1 [0.006 seconds, 169 bytes]
#> ● completed pattern Final_Presences
#> ▶ dispatched target unique_habitats
#> ● completed target unique_habitats [0 seconds, 94 bytes]
#> ▶ dispatched branch rarity_405e1cf7d36edc08
#> ▶ dispatched branch rarity_fcb1676d3b2f6824
#> ● completed branch rarity_405e1cf7d36edc08 [0.032 seconds, 4.786 kilobytes]
#> ● completed branch rarity_fcb1676d3b2f6824 [0.034 seconds, 7.006 kilobytes]
#> ▶ dispatched branch output_Rarity_c8f99e24ce7afc52
#> ● completed branch output_Rarity_c8f99e24ce7afc52 [0.043 seconds, 2.467 kilobytes]
#> ▶ dispatched target unique_species
#> ● completed target unique_species [0 seconds, 93 bytes]
#> ▶ dispatched branch export_presences_b7bf78e1c1a430c9
#> ● completed branch export_presences_b7bf78e1c1a430c9 [0.273 seconds, 0 bytes]
#> ▶ dispatched branch rarity_77d9a26761e4a007
#> ● completed branch rarity_77d9a26761e4a007 [0.045 seconds, 6.428 kilobytes]
#> ▶ dispatched branch output_Rarity_261466b6f238f521
#> ● completed branch output_Rarity_261466b6f238f521 [0.145 seconds, 2.469 kilobytes]
#> ▶ dispatched branch rarity_47ea97700de70215
#> ● completed branch rarity_47ea97700de70215 [0.015 seconds, 733 bytes]
#> ▶ dispatched branch output_Rarity_c2db253b33fcf9d9
#> ● completed branch output_Rarity_c2db253b33fcf9d9 [0.029 seconds, 2.473 kilobytes]
#> ▶ dispatched branch rarity_f4a6e9a8f4837219
#> ● completed branch rarity_f4a6e9a8f4837219 [0.029 seconds, 4.779 kilobytes]
#> ▶ dispatched branch output_Rarity_c1388be691e0be60
#> ● completed branch output_Rarity_c1388be691e0be60 [0.029 seconds, 2.467 kilobytes]
#> ▶ dispatched branch rarity_bee04486eb86e311
#> ● completed branch rarity_bee04486eb86e311 [0.016 seconds, 1.281 kilobytes]
#> ● completed pattern rarity
#> ▶ dispatched branch output_Rarity_7d8e043127d47e71
#> ● completed branch output_Rarity_7d8e043127d47e71 [0.028 seconds, 2.471 kilobytes]
#> ▶ dispatched branch output_Rarity_2cf706eb0499c812
#> ● completed branch output_Rarity_2cf706eb0499c812 [0.033 seconds, 2.469 kilobytes]
#> ● completed pattern output_Rarity
#> ▶ dispatched branch export_presences_9cb7df6f909cc656
#> ● completed branch export_presences_9cb7df6f909cc656 [0.243 seconds, 0 bytes]
#> ▶ dispatched branch export_presences_e0501a6e2e4e8857
#> ● completed branch export_presences_e0501a6e2e4e8857 [0.094 seconds, 0 bytes]
#> ● completed pattern export_presences
#> ● completed target Phylo_Tree [17.588 seconds, 654 bytes]
#> ▶ dispatched branch PhyloDiversity_405e1cf7d36edc08
#> ▶ dispatched branch PhyloDiversity_77d9a26761e4a007
#> ● completed branch PhyloDiversity_405e1cf7d36edc08 [0.159 seconds, 2.965 kilobytes]
#> ▶ dispatched branch output_PD_0fed6773594c8b8e
#> ● completed branch output_PD_0fed6773594c8b8e [0.07 seconds, 3.127 kilobytes]
#> ▶ dispatched branch PhyloDiversity_47ea97700de70215
#> ● completed branch PhyloDiversity_77d9a26761e4a007 [0.25 seconds, 3.696 kilobytes]
#> ▶ dispatched branch output_PD_9080f2064a157266
#> ● completed branch PhyloDiversity_47ea97700de70215 [0.025 seconds, 602 bytes]
#> ▶ dispatched branch output_PD_5144605bf3a4ac38
#> ● completed branch output_PD_9080f2064a157266 [0.031 seconds, 2.957 kilobytes]
#> ▶ dispatched branch PhyloDiversity_f4a6e9a8f4837219
#> ● completed branch output_PD_5144605bf3a4ac38 [0.157 seconds, 2.657 kilobytes]
#> ▶ dispatched branch PhyloDiversity_bee04486eb86e311
#> ● completed branch PhyloDiversity_f4a6e9a8f4837219 [0.176 seconds, 2.951 kilobytes]
#> ▶ dispatched branch output_PD_d34599733447ab6e
#> ● completed branch PhyloDiversity_bee04486eb86e311 [0.046 seconds, 919 bytes]
#> ▶ dispatched branch output_PD_c0ee68bb087b85bd
#> ● completed branch output_PD_d34599733447ab6e [0.029 seconds, 3.125 kilobytes]
#> ▶ dispatched branch PhyloDiversity_fcb1676d3b2f6824
#> ● completed branch output_PD_c0ee68bb087b85bd [0.032 seconds, 2.792 kilobytes]
#> ▶ dispatched branch output_Richness_0fed6773594c8b8e
#> ● completed branch output_Richness_0fed6773594c8b8e [0.028 seconds, 3.738 kilobytes]
#> ▶ dispatched branch output_Richness_9080f2064a157266
#> ● completed branch output_Richness_9080f2064a157266 [0.034 seconds, 3.945 kilobytes]
#> ▶ dispatched branch output_Richness_5144605bf3a4ac38
#> ● completed branch output_Richness_5144605bf3a4ac38 [0.028 seconds, 2.729 kilobytes]
#> ▶ dispatched branch output_Richness_d34599733447ab6e
#> ● completed branch output_Richness_d34599733447ab6e [0.028 seconds, 3.736 kilobytes]
#> ▶ dispatched branch output_Richness_c0ee68bb087b85bd
#> ● completed branch output_Richness_c0ee68bb087b85bd [0.044 seconds, 2.866 kilobytes]
#> ● completed branch PhyloDiversity_fcb1676d3b2f6824 [0.245 seconds, 4.238 kilobytes]
#> ● completed pattern PhyloDiversity
#> ▶ dispatched branch output_PD_32f01d33f95b1de0
#> ▶ dispatched branch output_Richness_32f01d33f95b1de0
#> ● completed branch output_PD_32f01d33f95b1de0 [0.031 seconds, 3.31 kilobytes]
#> ● completed pattern output_PD
#> ● completed branch output_Richness_32f01d33f95b1de0 [0.031 seconds, 4.093 kilobytes]
#> ● completed pattern output_Richness
#> ▶ ended pipeline [49.782 seconds]
#> Warning message:
#> 10 targets produced warnings. Run targets::tar_meta(fields = warnings, complete_only = TRUE) for the messages.
#> How It Works
The run_workflow function creates a pipeline that:
Reads the data from the specified file path.
Filters the data using the provided filter expression.
Cleans the species names to match the GBIF taxonomic backbone.
Counts the species presences within the specified geographic area (in this case, Aarhus).
Generates a buffer around the species presences within the specified distance, using a template raster.
Prepares the land-use data by generating a long-format table that matches each raster cell to its corresponding habitat types.
Predicts habitat suitability for each species across different land-use types using the
ModelAndPredictFunc, which models habitat preferences and provides continuous predictions.Generates habitat suitability thresholds for each species based on the predicted suitability scores, using the
create_thresholdsfunction to define the 90th, 95th, and 99th percentile thresholds.Builds a lookup table to determine the land-use types each species can inhabit based on the thresholds.
Generates the final species presences by filtering the buffered presences according to both the lookup table and the long land-use table, ensuring each species’ potential distribution is consistent with its habitat preferences.
Generates a phylogenetic tree for the species in the species list, using the
generate_treefunction.Generates a visual representation of the workflow if
plot = TRUE.
You can monitor the progress of the workflow and visualize the dependencies between steps using targets::tar_visnetwork(). The result will be similar to running the steps manually but with the added benefits of parallel execution and reproducibility.
This automated approach allows you to streamline your analysis and ensures that all steps are consistently applied to your data. It also makes it easier to rerun the workflow with different parameters or datasets.